LUCENE
검색엔진의 핵심요소
주제 1. LUCENE 개념과 소개
Lucene Library
- 확장 가능한 고성능 정보검색 라이브러리.
- Software 프로그램에 색인과 검색 기능을 간단하게 추가할 수 있다.
- Text 색인과 검색기능에 강점을 두는 Apache 라이선스의 오픈소스이다.
- 네이버 검색엔진에도 사용된다.
Lucene 공식 홈페이지에서의 소개글
Apache LuceneTM is a high-performance, full-featured text search engine library written entirely in Java. It is a technology suitable for nearly any application that requires full-text search, especially cross-platform.
Features
- Sacalable, High-Performance Indexing
- 1시간에 150GB 데이터 이상을 처리(검색)할 수 있다.
- Heap Memory로 1MB 이상만 있어도 정상적으로 작동 가능하다.
- Batch Indexing 만큼이나 빠른 인덱싱 속도를 보여준다.
- Powerful Search Algorithm
- Rank 기반의 Search결과(가장 최적의 결과 도출)
- 다양한 Query 제공
- Fielded Search(Metadata 검색 말하는듯…)
- 어떤 Field라도 정렬 가능
- Multiple index Search 가능
- 동시다발적 Update와 Searching이 가능
- 다양한 검색조건, Highlighting, join, grouping 가능
- Memory-efficient / typo-tolerant
- Configurable Storage Engine
정보검색기술(Information Retrieval)에 가장 근간이 되는 기술은 검색엔진(Search Engine)이다.
검색엔진은 크게 2개의 영역으로 나뉘어진다.
검색과정
- 사용자로부터 검색 질의를 받아 분석&분리
- 색인에서 분석된 단어들이 들어갔는지 검색
색인과정 - 타겟 문서에서 텍스트를 추출하여 분리
- 해당 단어가 어떤 문서(Document)에 들어가있는지 자료구조 형성
그림으로 그려보면 이렇게 보여진다.
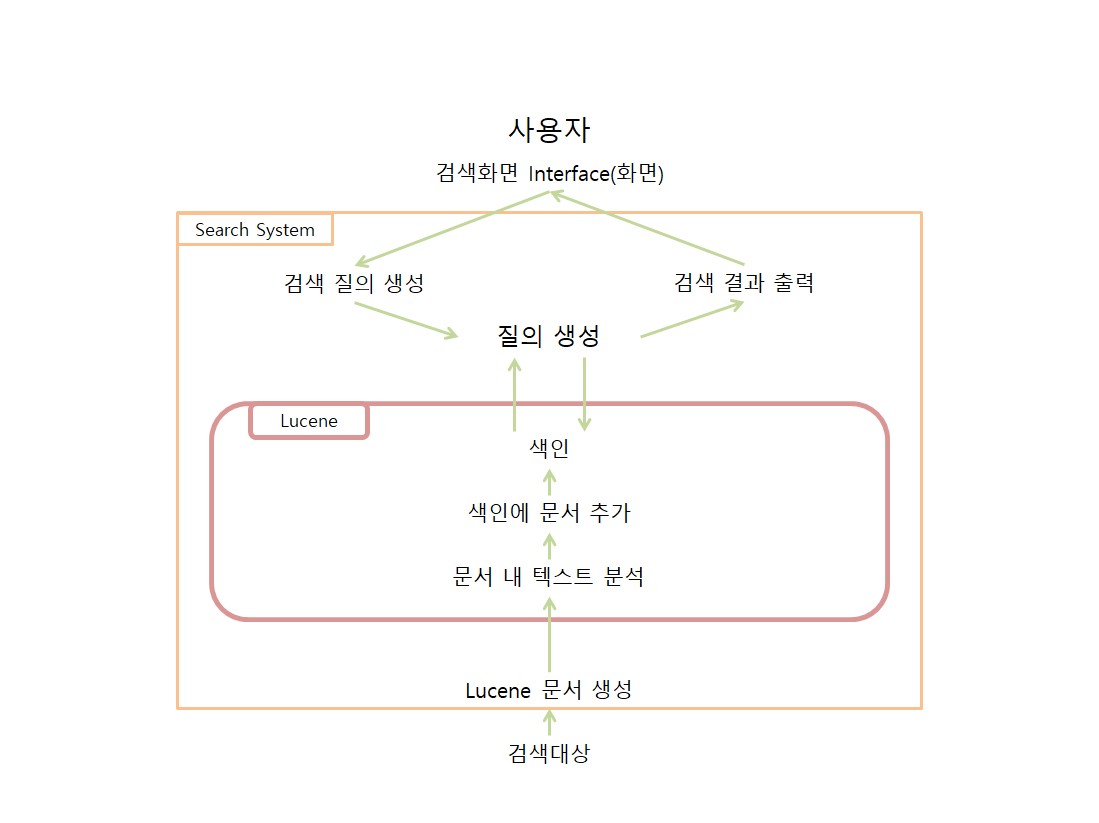
해당 그림을 보면 Lucene이라고 박스를 해놓은 것이 있는데, 이 박스가 Lucene Library에서 지원해주는 기능 그 외 모든 기능과 흐름은 개발자가 직접 만들어주어야 한다.
그 중 가장 중요하고 어려운 일은 위에서 언급한 사용자의 검색 질의를 분석한다는 것.
나중에 깊게 다루겠지만 영어와 달리 한국어는 이 분석이라는 것이 세상에서 제일 어려운 언어이다. (네이버에서 이 분석 연구를 위해 언어학 전문가를 영입한다는 소문도…)
Written on September 2, 2020
