주식 분석 스트리밍 3
Spark Streaming을 개시합니다.
[Spark]
Spark Streaming을 얘기하기 전에, Spark라는 것부터 얘기해볼 필요가 있다.
아파치 재단의 오픈소스로 관리되고 있는 인메모리 기반의 데용량 데이터 고속처리 엔진으로 범용 분산처리 컴퓨팅 프레임워크이다.
Spark의 특징으로 몇 가지가 있다.
- Speed
- In-Memory 기반의 빠른 처리가 가능하다.
- Ease of Use
- 다양한 언어를 지원한다. (Java, Scala, Python, R, SQL(Structured))
- Run Everywhere
- YARN, Mesos, Kubernetes 등 여러 클러스터 지원
- HDFS, HBase, Casandra 등 다양한 포맷 지원(특히 Hadoop EchoSystem에 최적화된다.)
Spark는 특유의 데이터 관리 프레임을 가지고 있다.
- RDD
- Resilient Distributed Dataset
- 스파크의 가장 기본이 되는 데이터 구조
- 스파크의 모든 연산은 RDD를 만들거나 변형(Transform)하거나 연산(Action)하는 작업들이다. (Spark Low-Level 작업이라고도 한다.)
- 메모리에서 데이터공유가 이루어지기 때문에 디스크 I/O보다 최대 100배 빨라지지만 Fault-tolerant를 방지하기 위해 Read-Only, Immutable하도록 만들었다.
- 데이터를 함수형 프로그래밍으로 조작하고자 할 때 유용하다.
- 데이터가 비구조화되어있을 때 유용하다.
- 밑에서 얘기할 Streaming의 기본 구조도 RDD 형식으로 처리한다.
- DataFrame
- RDD와 달리 RDBS처럼 컬럼이 존재하는 데이터 구조로서, 대용량데이터를 쉽게 처리할 수 있고 기존 데이터 엔지니어들이 더욱 쉽게 Spark를 처리할 수 있게 되었다.
- DataSet
- Spark의 Structured API (이런 부수적인 용어들은 나중에 따로 정리하도록 하겠다.)의 기본적인 데이터 타입으로 DataSet을 Row타입으로 정의하면 DataFrame이 된다.
- 도메인 별 Encode를 적용하여 특정 객체 T를 내부 데이터타입으로 매핑하는 시스템을 의미한다.
- 예를 들어, 계좌정보를 분석하기 위한 도메인 객체 T1과 주식 종목 별 데이터 분석 도메인 객체 T2를 따로 만들어 매핑할 수 있다는 의미이다.
[Spark Streaming]
Spark Streaming은 위에서 언급한 Spark를 실시간 분석용으로 재설계한 프레임워크이다.
기존 Spark가 전날 로그데이터를 전부 긁어모아 한번에 연산을 하는 시스템이라면, Spark Streaming은 실시간으로 사용자들이 클릭하는 조회결과 데이터 혹은 머신러닝 실시간 학습등에 최적화 되어있다.
실시간 데이터 Stream을 받아서 데이터를 DStream(Distretized Stream)이라는 추상적인 배치 단위 데이터로 나누고 이를 Spark Engine으로 분석할 수 있다.
[DStream]
DStream은 시간 별로 도착한 데이터들의 RDD 집합이라고 할 수 있다. 실시간으로 데이터를 받기 때문에 시간이라는 자원과 엮일 수 밖에 없는데, 이를 고민해야 하는 원인 중 하나는 처리시간이다.
외부에서 받아오는 데이터가 축적되는 시간을 기준으로 Spark 분석을 진행한다고 해보자. 그런데 데이터 양이 생각보다 너무 방대하다. 아직 처리가 되지도 않았는데 다음 데이터가 들어오게 되면 점점 빚처럼 늘어나는 것.
이를 위해서 Windowed DStream이라는 개념을 추가하게 된다. Time 별로 데이터가 들어오지만, 이를 바로 처리하는 것이 아니라 그대로 Memory에 대기시켜 두었다가 Windowed DStream 처리 간격마다 한번에 처리하는 것이다. 이 때 처리 간격은 쌓이는 데이터의 양과 처리속도, 실질적인 업무 시간 등을 적절히 고려한 임계값이어야 할 것이다.
[개발환경 구축]
그렇다면, Spark Streaming 개발환경을 구축해보자. Linux 실행환경은 추후에 해보도록 하고, 지금은 로컬 개발환경만 진행해본다.
네이버 인턴생활 당시 듣도 보도 못했던 Spark란 걸 개발해보기 위해 일주일동안 개발환경 구축만 했던 경험을 되짚어보며 진행해보았다.
- IDE 선정
- Eclipse와 VS Code도 훌륭한 IDE이지만, Intellij만큼 사용자 친화적인 IDE는 본 적 없는 것 같다. 또한 Scala를 사용하는데 있어서 Intellij Plugin이 너무 잘되어있어서 다른 IDE를 선택할 여지가 없다.
- Language
- 앞서 얘기한 것 처럼 Spark는 정말 다양한 언어를 지원하고 있다. API 천국인 Java와 Pyspark라는 이름으로 Python도 지원한다. 또한 Java 파생형으로 만들어진 함수형 프로그래밍 언어 Scala도 있으며 데이터 분석전용언어 R도 사용할 수 있다.
- 나름 사용해봤다고 친한 Scala로 정했다.
- 왜 자바가 아닌 Scala?
- Scala는 강조해둔 것처럼 함수형 프로그래밍 언어이다. Java처럼 OOP인 성격도 가지고 있어서 개발하기 용이한? 부분도 있지만 함수형 프로그래밍 자체의 간편하고 Lambda식 효율높은 코드처리가 가능하다.
- Build Tool
- Gradle을 선택하였다. Maven보다 더 구성이 편하고 기능이 많은 Gradle을 선택하였다. 무엇보다도 Build 속도가 더 빠르다.
- SBT라고 하여 Scala Build 전용 툴이 존재한다. 하지만 Jar 형태로 말아 Airflow에 독립적으로 등록하려면 Gradle 빌드 툴이 더욱 알맞다고 판단했다.
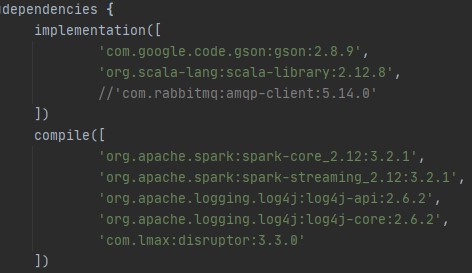
기본적으로 Spark를 위한 Dependencies들을 다운받았다.
Spark Core와 Streaming을 보면 *_2.12:3.2.1 로 되어있다.
앞 2.12는 Scala 메이저버전을 의미한다. 위 scala library를 보면 동일하게 2.12 버전으로 되어있음을 알 수 있다.
뒤 3.2.1은 Spark 버전을 의미한다. (Spark 2와 3은 쿠버네티스를 이용한 클라우드 시스템 강화, JDK 버전 및 python 3 사용 가능하도록 추가되었다는 점이 다르다. » 중요 Core 큰 틀은 안바뀌었다.)
rabbitmq는 다음 게시글 관련 스포
[Streaming을 한번 돌려보자]
전체코드부터 보자
object TradingApp {
private val master = "local[*]"
private val appName = "TradingSystem"
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(appName).setMaster(master)
val sc = new StreamingContext(conf, Seconds(5))
val data = sc.socketTextStream("localhost", 9098)
val words = data.flatMap(_.split(" "))
val maps = words.map(word => (word, 1))
val result = maps.reduceByKey(_ + _)
result.print()
sc.start()
sc.awaitTermination()
}
}
Scala 및 Spark 기본적인 문법과 의미는 생략하도록 하겠다.
val만 해도 설명할게 한 페이지라…
부분적으로 간단하게 설명을 써보면
private val master = "local[*]"
private val appName = "TradingSystem"
master는 클러스터 매니저를 선택하기 위한 옵션이다.
코드에서 기술한 local[*]은 로컬 컴퓨팅 내에서 worker들을 생성하며 CPU에서 가용 thread를 전부 끌어오는 것을 말한다.
‘*’ 대신에 특정 숫자를 넣으면 해당 수만큼 worker가 만들어진다.
local 외에도 mesos, yarn, k8s 등을 옵션으로 넣을 수 있다.
appName은 SparkContext에 등록할 어플리케이션 이름이다.
val conf = new SparkConf().setAppName(appName).setMaster(master)
val sc = new StreamingContext(conf, Seconds(5))
SparkConf 객체에 위에서 설정한 master와 appName을 기입한다. 이 외에도 많은 설정값이 있으니 필요한 값을 넣어주면 된다.
그 후 StreamingContext를 생성한다. Spring에서 ApplicationContext를 생성하는 것과 같은 이치이다.
이 때, 주목할 점은 Seconds 이다. 예상되는 대로 Spark Streaming에서 기준을 잡는 Timer이다. 여기 등록하는 Timer를 기준으로 Windowed Timer 등을 설정해야 한다.
val data = sc.socketTextStream("localhost", 9098)
val words = data.flatMap(_.split(" "))
val maps = words.map(word => (word, 1))
val result = maps.reduceByKey(_ + _)
result.print()
StreamingContext를 생성한 후 InputStream을 설정한다.
socketTextStream은 Socket을 통해 Text 데이터를 Input으로 받는 Context 함수. Host와 Port를 args로 넣어주면 Socket을 생성한다.
Spark Get Started에서 보여주는 Word Counts 예시로서 기본적으로 많이 쓰이는 함수들이 보인다.
flatMap: 각 Element 별로 Lambda를 적용하는 함수. 각 Element 별로 Lambda를 적용하는 map과 달리 하나의 row로 묶어 한 번에 Lambda를 적용한다.
코드 상에서 _.split(“ “) 이라는 함수를 적용하면 space 별로 String을 split하여 Array를 만들라는 의미이며, 여러 줄일 경우 하나의 Array를 반환한다.
밑에 보이는 map은 하나의 Array로 만들어진 단어들을 pair-2를 1로 고정한 Tuple로 만든다.
reduceByKey: reduce란 map과 반대되는 함수로, map이 하나의 Collections을 산개하는 역할이라면 reduce는 산개되어있는 데이터를 특정 기준으로 모은다.
함수 이름처럼 Tuple같은 Key-Value 식으로 되어있는 데이터를 key 기준으로 reduce해준다.
‘_ + _’ 라는 것은 각 데이터의 value를 더하라는 lambda.
마지막으로 print하면 끝.
sc.start()
sc.awaitTermination()
Spark는 Implicit하게 실행을 시작하지만, Spark Streaming은 start()를 명시적으로 해주어야 시작한다.
그럼 위 StreamingContext에 연결되어있는 함수를 Timer 별로 받은 데이터에 적용시키는 것이다.
작성한 코드를 실행해보자.
linux에서 nc -lk [PORT] 명령어로 소켓 클라이언트를 손쉽게 열 수 있다.
밑 사진은 Windows10 Ubuntu에서 실행한 것이다.

이렇게 테스트 문구를 입력한 뒤 Spark Streaming 실행 로그를 보자
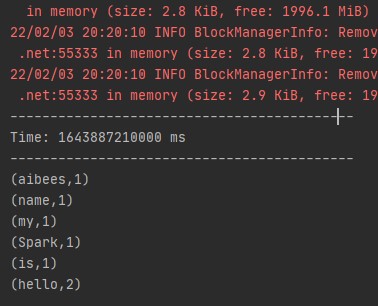
다음과 같이 단어 별로 분리되어 Tuple이 만들어져 있고 ‘hello’는 2개이므로 tuple value가 2임을 알 수 있다.
![]()
